这是一篇比较长的教程. 但你仍然需要仔细阅读以确保能正确的在集群上运行程序.
如何利用SLURM在集群上运行程序
Last modified: December 10, 2024
服务器上已经有很多用户在运行程序了, 你不可以和其他人一起抢占资源 (最终导致炸服). 另外, 我们的登陆节点性能也不如计算节点好(一个节点通常指一台机器).
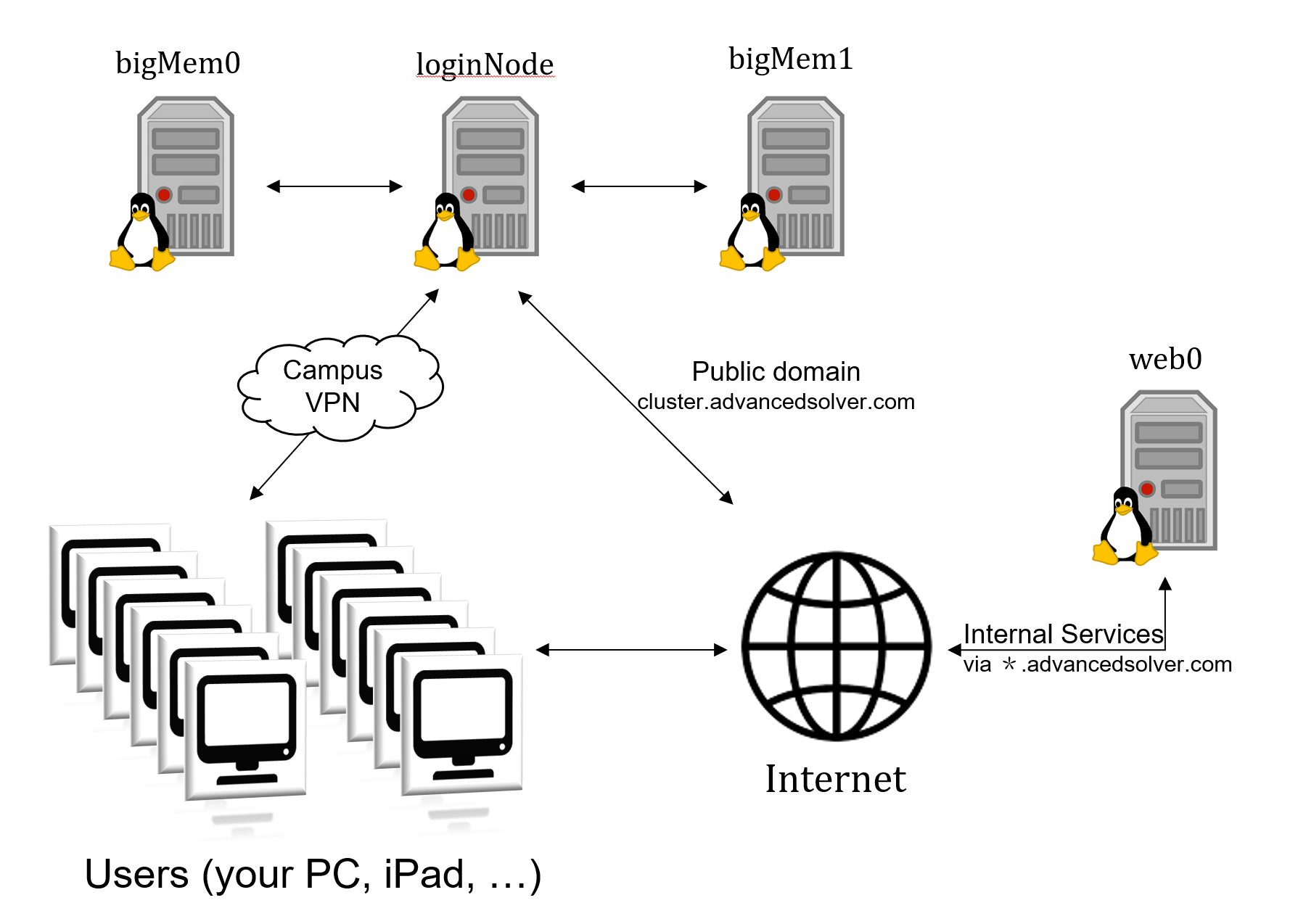
我们的服务器集群使用 SLURM, 一套自动化资源分配的作业调度工具, 帮助你提交作业到计算节点上运行. 当你的程序需要很长的运行时间或者很大的内存占用时, 请使用 SLURM 提交程序. 下文介绍了如何使用 SLURM 提交程序.
我们以对其他用户可能造成的影响来衡量一个任务是否适合在登录节点临时运行.
例如, 以下是你可以在登录节点上临时运行的程序:
- 已知仅使用极少数核心的程序 (例如 C, C++ 程序默认为1核, 不调用
numpy, pandas等库的简单 Python 程序), 不超过10分钟- 已知使用半数左右核心的程序 (例如经过手动控制并行程度的 C, C++ 程序), 不超过3-5分钟
- 可能会使用全部核心的程序 (例如 MATLAB, 涉及
numpy, pandas等并行计算库的 Python 程序), 不超过1分钟例如, 以下是你必须要去计算节点上运行的程序:
- 预计可能会使用超过 32G 内存的程序
- 预计运行时长超过 10 分钟的程序
- 预计其中计算密集部分超过 1 分钟的程序
SLURM提供了三种提交作业的方法:
- 👉
srun: 将你当前要运行的一条指令提交到计算节点上运行. 优点是最容易使用, 缺点是只能运行一行代码 (因此无法提前设置环境变量等). 如果你想要运行的命令一行不够, 比如需要在运行命令之前加载模块, 或者设置环境变量等, 可以用下面的salloc或sbatch. - 👉
salloc: 为需要实时处理的作业分配资源, 系统会为你分配一个或多个计算节点, 然后你可以登陆到计算节点上, 使用交互式命令行. 这一用法适用于需要互动处理的作业. - 👉
sbatch: 提交作业脚本, 系统会为你分配一个或多个计算节点, 运行你的作业. 这一用法适用于放在后台慢慢跑的作业.
点击链接, 查看更多说明.
每个用户可以同时启动的任务数量不是无限的. 我们有一个 核时limit 来控制用户的新任务是否允许开始运行.
当前 limit: (48 * 24) 核时
计算方法: 对该用户所有运行中任务的 核数乘以预计完成所剩余的时间 求和, 得到当前预计剩余所需核时.
- 当你提交的新任务设定的完成时间和核数超过了 limit, 则该任务无法运行. 此时需要减少核数或者设定的时间上限.
- 新提交的任务所预期的核时如果会使当前运行任务总核时超过 limit, 则该任务会被强制排队, 直到你已经运行的任务完成, 或占用的核时足以让新任务开始运行.
如何指定作业时限、核数等参数呢? 请查看 👉申请资源选项.
sinfo, squeue, scancel, scontrol等其它slurm命令可以帮助你更好地了解服务器状态与作业状态. 请查看 👉其他常用命令.
如果希望在固定时间使用节点, 请查看: 👉🆕预约节点资源.